Expectation Maximization (EM)
A widely applied parametric counterpart to soft-k-means clustering for acquiring prototypes on a measurable space is based on the assumption of i.i.d. random samples and by the following parametric family of mixture distributions:
with unknown parameters:
Here, the different parameters parameterize the mixture distribution on that partitions the set into different clusters with proportions , where each has the density .
Starting from this statistical perspective, where an approximation to model parameters is given, clustering amounts to fitting the mixture distribution by estimating true model parameters via maximum log-likelihood estimation of:
Making a further assumption that each is generated by exactly one component distribution and augmenting the set:
where corresponds to class assignments of points to the associated distribution , optimization is performed by instead maximizing the following lower bound to :
Maximization of this lower bound amounts to performing the so-called EM-iterates (expectation-maximization), see [Bishop, 2007], that result in the updates with initialization :
EM Algorithm Updates:
-
Expectation Step:
-
Maximization Step for and :
The procedure consists of two main steps: expectation over the conditional distributions yielding a lower bound for the objective , and maximization over parameter .
Exponential Family Distribution Case:
For the case where the components belong to an exponential family of distributions represented in terms of Bregman divergence:
where parameters are expressed via conjugation through:
The EM updates simplify to:
-
Expectation Step with Bregman Divergence:
-
Maximization Step:
where the final step admits a closed-form solution similar to mean shift updates:
For detailed treatment of EM iterates in connection with Bregman divergences, see [Banerjee, 2005].
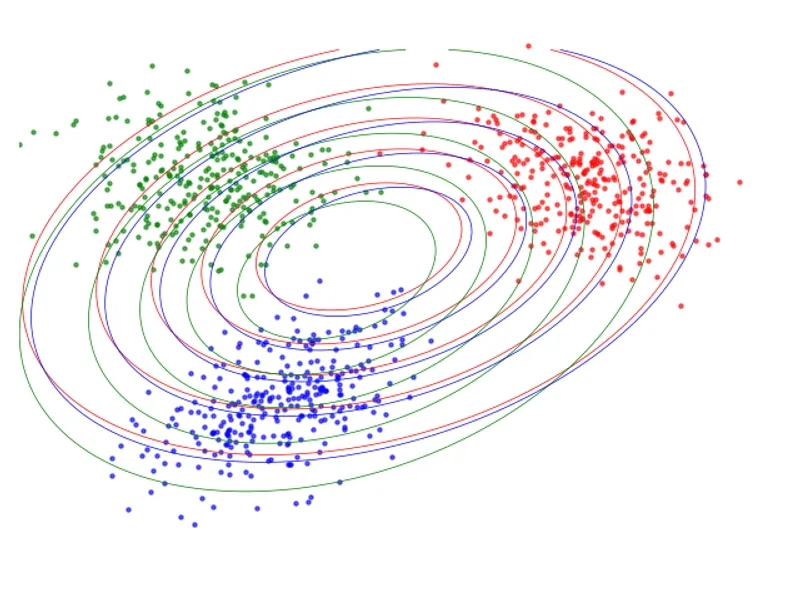
Lets consider a simple example of applying the EM algorithm to fitting a mixture of 3 gaussions. Given a data set generated from with