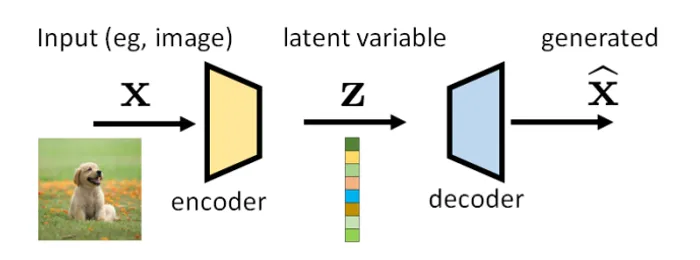
Vartiational Autoencoders become popular with the work of Kingma and Welling (2013). The primary goal was the inference task of latent distribution
over small instrictic dimension thereby reducing the large dimensialel data space .
Chalenges:
Evaluating the model evidence is a hard task due to the involved integral. As can be easy evaluated this implies that the conditional distribution can not be accessed.
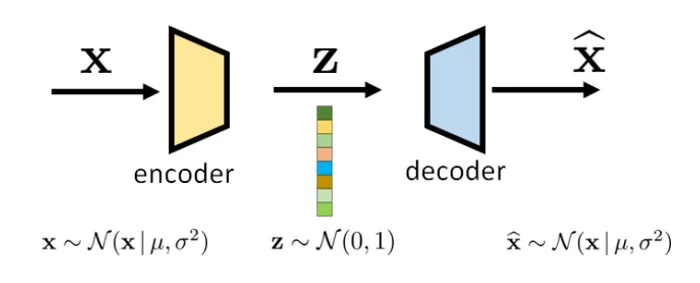
Variational Autoencoders assumes builds upon two variational distributions and which conditioned on the input random variable are denoted as the decoder and the encoder respectivaly.
Hereby, common choices of the decoder and the encoder are assumed to be gaussian distribution whose mean and covariances are the deep paramterized by an neural network.
The lower bound to the log-likelihood after skipping the nonnegative Kullback Leibner divergence is denoted as the Evidence-Lower-Bound Objective (ELBO). Therefore by maximizing the (ELBO) we follow the hope that corresponding maximimzer of the Encoder Decoder part yield a maximmal log probability distribution .
Lets summerize our goal which potentially aim to achieve to get an optimal variational auto encoder:
(1) We want an approximation to the truth data generating distribution,
p∗(x)≈p^(x)=∫Zpθ(x,z)dz
which also highlights the burden to evaluate the conditional distribution over the latent space corresponding to the decoder which by Bayes rule requires knowledge on which is unknown.
by marginalizationg of the decoder.
(2) By contruction the encoder and the decoder must satisfy the self-consitancy relation at the latent marginals , i.e.
∫Xpθ(x,z)dx=q(z)=∫Xqϕ(x,z)dz
The distribution over the latent space is commonly chosen to be a simple distribution to allow efficient sampling from the decoder under assumption on tractable form of
(3) Zero gap which makes the ELBO lower tight that is
DKL(pθ(z∣x)∣∣qϕ(z∣x))≈0
Let us consider how all this goals are adressed by minimizer of the ELBO objective which can be equivalently written as
The result of this simple decomposition of the ELBO highlights maximization simultaniosly measures how well the encoder distribution confirms to the desired simple marginal by maximizing the first term which is responsible for data compression. Moreevoer maximal values of the ELBO enforce the second term to be close to zero,
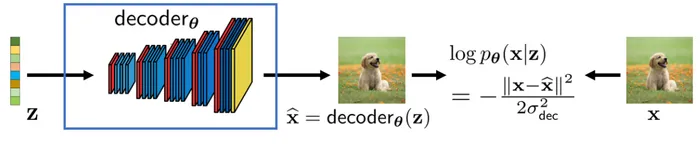
which measures the generative accuracy of the data point passing through the encoder to yield high probability samples which are close to the original signal (data) .
Gaussian VAEs
Lets consider a simpel scenario of an VAE where the encoder and the decoder are given by Gaussian distributions
where the mean and covariances are now paramterized by a neural network, for example the mean as a vector and diagonal of the covariances. Taking the prior latent distribution the evaluation of the (ELBO) is approximately achieved by\
Sampling over the encoder distribution which is Gaussian and therefore tractable
Evaluating the brackets within the expectation which are given in closed form solution
where we put all the contants undependent of into the constant . Taking a minibatch of the training the parameters are then optimized by batch gradient descent
∣B∣1∑x∈BLELBO(x,ϕ,θ)
Forward Pass
Given a dataset of independently and identically distributed data points
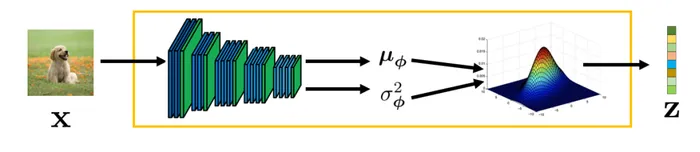
the optimization of the encoder decoder boilds down to the following steps. First Picking a random sample we need to pass the data through the encoder by sampling a latent variable . This is
accomplished by taking a neural network and to pass the input data and output given by the mean and and covariance matrix . Subsequently, the sampling a latent variable is performed by applying tranformation mapping to gaussian white noise via
z=μ(ϕ(x))+Σ(ϕ(x))21ϵ
where the square root of the covariance matrix is obtain by applying Cholesky decomposition.
Following similar steps the sampled is passed as the input to the second neural network which parametrized the mean and covariance of the decoder distribution with
Problem with naive Gradient Descent
Having performed the forward pass we need to evolve the variational paramters towards a local mimimum of the ELBO objective via gradient descent where the gradient with respect to and are respectivaly given by
which can be apprxomited by a one sample Monte Carlo estimator
≈∇θ(logpθ(x,z)−logqϕ(z∣x))=∇θ(logpθ(x,z))
As can be observed from the above formula, despite a simple Monte Carlo approximation there are no difficulties in accessing the gradient for the backward propagation of variational paramters . However, this is not the case for the gradient with respect to the encoder
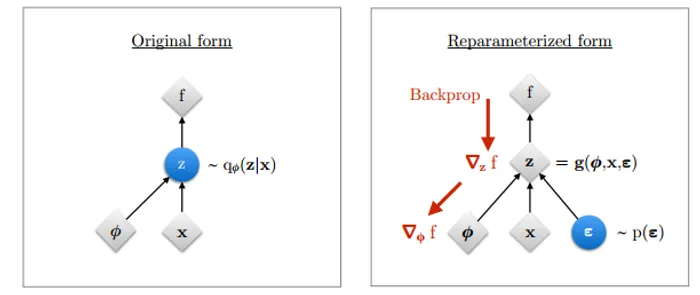
which is due to the neccecity to differentiate the expectation over which is paramterized by !. To tackle this problems we need to introduce the reparametrization trick.
Reparametrization Trick and Changes of Variables Formula
Concerning the problem of evaluating expression (todo) Rezende et al tackled the problem via the change of variables formula for continuous distributions
fX(x)dx=fY(Ψ−1(x))det(JxΨ−1(x))dx
where and denote probability densitity distributions respectivaly. To see why the above formula holds let us do some simple calculations given an invertible map with . Because maps random variables one to one to some we first reexrpress the density to using abbreviation
where the fourth inequality holds due to positive determinant of the map . Finally, applying the classical change of variables formula for intergrating multivariate functions with respect to substitution
Consider the following simple 1D exmaple with Gaussian distributed random variable . Then the transformed term is again a randmom variable with nonnegative derivative and using change of variable formula we know the density of
as can be observed by the following figure
Illustration of Change of Variables Formula
Using the change of variables we can reparametrize the expectation of in terms of standart Gaussian random variable by looking for a mapping
which yields with
which equals . The important observation of the above reparametrization trick comes from the changed expectation from that depends on to a simple standart Gaussian distribution . Moreover this yields an efficient evaluation of the gradient with respect to the problematic variational paramter
In other word reparamterization trick makes it possible backpropage through the encoder part of the network as can be observed from the following figure
For a one sample Monte Carlo estimator with and evaluation of the ELBO amount to compute
which yields an unbiased estimator as can be observed from
i.e. the expected gradient with respect to white noise distribution results in the exact expression of the truth gradient of the ELBO objective.
Lets next consider the building blog of evaluating the remaining parts of the one sample ELBO approximation.
Calculation of encoder log probability given a data point mainly connects to the choice of a proper invertible mapping and tractable density . Using the change of variables formula the computation boils down to
which in particular shows that tractable mappings are those which Jacobian is upper or lower triangular matrix where an important class of such mappings is given by assumming the mean-field like strucutre of the encoder
Then the mapping can be contructed from the transformation of gaussian distribution under linear transofmation, i.e. via
with Jacobian given by a simple diagonal matrix with covariance at the diagonal.
More generally, we can generalize the above case to using Cholesky factorization with invertible mapping with closed form of the encoder
Hereby, the parametrization of in terms of neural network can be achieved in two steps
First
Second, applying a masking matrix with zeros above the diagonal via .
Chalenges
The model can be trapped within undesirable stable equilibrium which happens when in the first optimization steps is low and
Blurriness Artifacts for nonzero KL-divergence between and which causes the variance of the decoder to be higher then variance of the encoder and the data